Unlocking peak performance on IBM Quantum Nighthawk devices with crosstalk suppression


In January 2026, IBM released its Nighthawk quantum processing unit (QPU) to select IBM Quantum Platform users. With the highest coherence times to date, the Nighthawk-powered ibm_miami is an extremely impressive device, designed with an architecture to complement high-performing quantum software to deliver quantum advantage.
The benefits of longer coherence times are offset by longer gate durations, and overall two-qubit gate-error rates are higher on ibm_miami than the best of its predecessor IBM Quantum Heron devices.
In this blog, we explore how Nighthawk's grid topology enables highly efficient compilation of quantum algorithms. Most importantly, we show how software-level crosstalk-error suppression is essential to achieve the highest performance possible on the new device.
Based on what we’ve seen, we’re excited about the augmented connectivity that Nighthawk will bring in the near term as the next generation of devices is made public.
The benefit of a 2D grid topology
A significant technical difference between Nighthawk and Heron devices is the increased level of connectivity among the qubits. ibm_miami’s Nighthawk has qubits arranged into a square lattice topology, rather than Heron devices’ heavy-hex pattern. In a grid topology, more qubit pairs are directly linked. Most qubits are connected to four neighbors, as opposed to only two or three neighbors for heavy-hex configurations. This represents a 60% increase in connectivity on average.
In general, entangling arbitrary qubit pairs requires a series of SWAP operations to move data around the chip to a point where direct coupling is possible. With a larger number of directly coupled qubits, there’s a greater chance that an arbitrary pair can be entangled natively via a single application of a two-qubit gate. The result is that quantum algorithms can be compiled onto the device with fewer gates, shallower circuit depth, and shorter overall duration.
This is great news for performance: fewer gates means fewer opportunities for errors. Lower circuit depth and duration mean that complex algorithms can be completed within the time limits imposed by decoherence, especially given ibm_miami’s long coherence times.
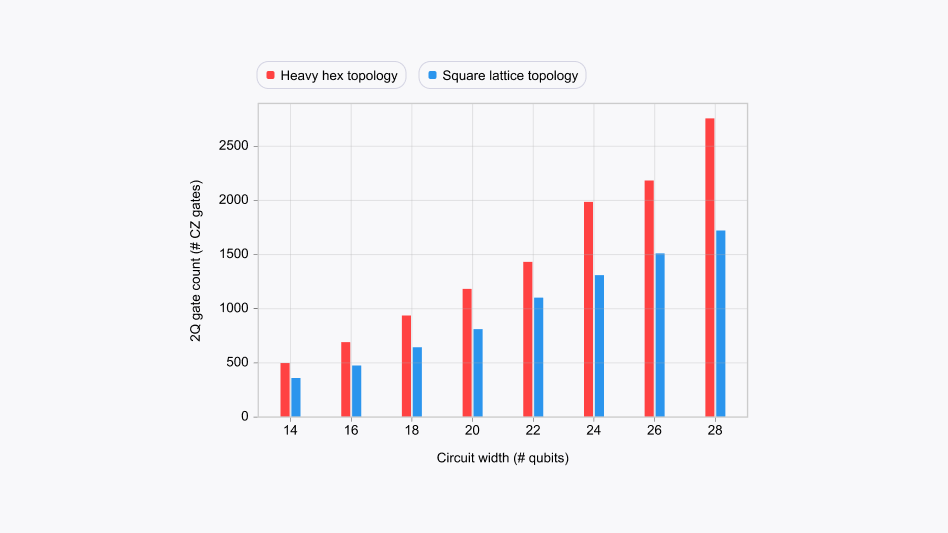
To illustrate the benefits of the grid topology for quantum compilation, we have compiled Quantum Fourier Transform algorithms of various circuit widths (measured in the number of qubits in use) onto two different IBM devices, which differ in their two-qubit-connection topologies. It’s apparent, as shown in Fig 1, that the increased connectivity leads to dramatically improved two-qubit-gate counts. For this simple demonstration, we used the Qiskit transpiler and chose the highest available optimization setting.
The challenge of crosstalk (and the solution)
There’s no such thing as a free lunch; the increased connectivity of ibm_miami’s Nighthawk increases an existing challenge: crosstalk.
Unwanted interaction between qubits is a major source of error in quantum computing. The problem is exacerbated by the degree of connectivity. Even small amounts of quantum crosstalk (residual interactions that occur even in the presence of perfect signal transmission or coupling) can spread rapidly through the circuit due to the high density of connected qubit pairs. Before you know it, the delicate quantum state is degraded beyond recognition. The result is that the quantum circuit fails to correctly realize the desired algorithmic logic.
In order to take full advantage of NIghthawk’s long coherence times and favorable compilations, crosstalk must be actively suppressed with software. After all, long coherence times are not much use if the desired quantum state is rapidly lost due to crosstalk.
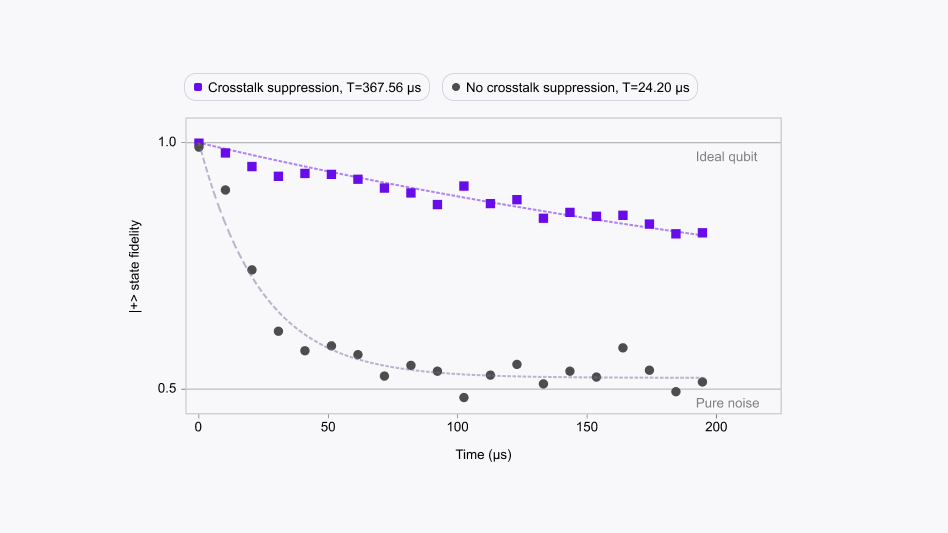
To illustrate how quickly quantum coherence is lost due to crosstalk and how effective suppressing it with software can be, we ran a simple quantum memory experiment, shown in Fig 2 below.
An equal superposition of |0> and |1> was prepared on each qubit on ibm_miami’s Nighthawk. After a variable delay, we measure whether the prepared state has been preserved or lost. “Bare” evolution without any countermeasure leads to an extremely rapid decay. What can we do about this?
The solution we’ve frequently relied upon is based on an error suppression strategy in the form of dynamical decoupling. This approach helps prevent decoherence and preserve the quantum state.
The choice of dynamical decoupling embedding significantly impacts our measured decay rates. The simplest approach simply injects so-called “echo” pulses in a regular pattern into the waiting period when the qubits sit idle. A more clever approach staggers the timing of these operations in such a way that crosstalk across any arbitrary pair can be efficiently suppressed, as we’ve shown in our technical manuscript.
For example, in Fig 2, we observe that in the presence of “standard” dynamical decoupling without crosstalk suppression, qubit #10 has a decay time-constant of 24 μs. Not bad. But with crosstalk suppression, the signal lasts about 15 times longer, reaching a time-constant of 368 μs! There are no extra operations required; we simply define the locations of the operations correctly in time, and we’re able to suppress crosstalk.
This trend is consistent across the entire processor, as seen in Fig 3. Analysis of the full dataset reveals that every qubit exhibits an increased effective T2 time when crosstalk suppression is active. The median sixfold improvement represents a significant extension of the quantum state's operational lifetime, which we attribute entirely to the active suppression of crosstalk.
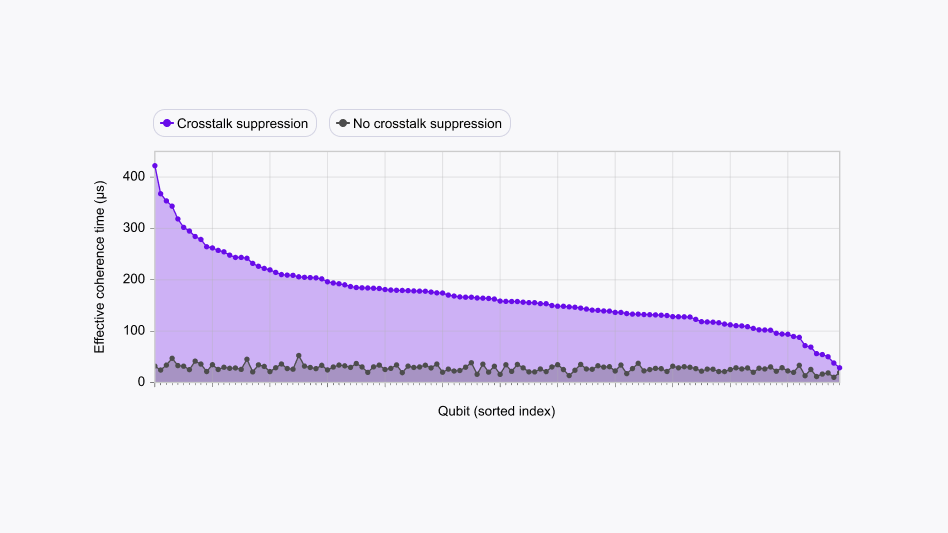
In addition to the boost of median fidelity, we can see that the best coherence times available on the device are significantly improved using active crosstalk suppression. Without suppression, the longest-lived qubit lasts for 52 μs. With suppression, the top thirty qubits have coherences that last longer than 200 μs, and the longest-lasting qubit now has a coherence time of 422 μs.
What about quantum algorithms?
The point of the quantum computer is to run quantum algorithms, and crosstalk suppression is essential to harnessing the full potential of the Nighthawk device.
We created a Quantum Fourier Transform circuit with a width of 14 qubits, compiled using Qiskit, and submitted it to the IBM Quantum Platform. The result: the correct target bitstring was observed about 5% of the time. This is not bad; the remaining 95% of the shots each produce the wrong bitstring, but these noisy data are spread out over very many different observed bitstrings. The 5% “on-target” forms a strong modal signal on the correct result.
Recognizing the importance of dynamical decoupling, we resubmitted the same transpiled circuit and used an additional runtime flag in the IBM Sampler V2 execution mode:
options.dynamical_decoupling.enable = True
This flag tells the IBM Quantum Platform to insert dynamical decoupling pulses into our circuit, and thereby execute a more noise-resilient version of the same algorithm. The inclusion of dynamical decoupling boosted the performance dramatically. With decoupling enabled, 17% of the shots hit the correct bitstring, which represents a more than threefold improvement. In general, it’s a good idea to use dynamical decoupling for almost all quantum circuit executions.
At Q-CTRL, we have developed a way to embed error suppression into any algorithm with particular attention to crosstalk suppression. While many workflows now include basic dynamical decoupling, our core error suppression technology uses specialized techniques to mitigate crosstalk more effectively. See what happens when we use Q-CTRL’s dynamical decoupling:
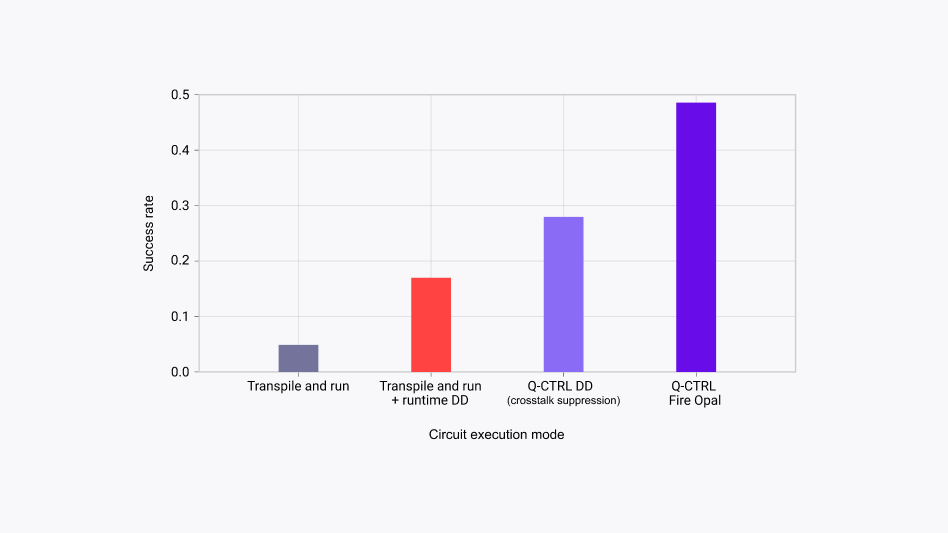
Now the circuit success rate is 28%. This is a nearly sixfold improvement over the bare circuit submission, and 65% higher than using the standard decoupling embedding available via the IBM Quantum Platform! Everything about these three circuits is identical except for the method of incorporating dynamical decoupling. Only Q-CTRL decoupling has the ability to suppress all crosstalk errors across the entire circuit. This example shows that crosstalk suppression is very important to unleash the highest performance available on the new Nighthawk device. These unique methods are available within the Fire Opal error-suppression technology in our Performance Management Qiskit Function, allowing you to take full advantage of the latest IBM Quantum hardware.
Get the full Fire Opal experience
Crosstalk suppression can help unlock the high performance of quantum algorithms on the current Nighthawk device, but there are also other circuit optimization techniques that can produce substantial performance benefits. More efficient compilation and circuit synthesis, layout selection, readout-error mitigation, and crosstalk-error suppression all combine to maximize the available performance on real quantum computers.
Our Fire Opal performance management software handles all the details with no configuration required of the user. The result is the highest possible performance for your algorithm on any available quantum processor.
When we submit the same circuit to ibm_miami via Fire Opal, we see the full potential of the Nighthawk device. Observed fidelity is now 48%. There have been no changes to the underlying hardware, and we don’t use any form of special “God mode” developer access. We’ve just combined our expertise in AI and physics to configure the logical circuit just right for high-fidelity execution on real hardware.
This performance gain is reliable and reproducible across different circuit sizes. We prepared a range of Quantum Fourier Transform circuits of different qubit widths, comparing a standard workflow against Fire Opal. The standard workflow is to compile with Qiskit on the highest optimization setting, then submit the circuit to the IBM Quantum Platform (we try both with and without the runtime dynamical decoupling enabled). The Fire Opal workflow is simply to generate the algorithms—no compilation—and submit via the Fire Opal API. As we see in Fig 5, in all cases, Fire Opal produces the best results.

IBM’s first Nighthawk processor is an impressive device. The baseline performance is exceptional, and the added connectivity can dramatically simplify circuit compilation, instantly producing better outcomes. Fire Opal software can fully suppress the residual crosstalk and deliver performance on the edge of what’s possible in the field.
Stay tuned for more exciting hardware and software advancements from the teams at IBM and Q-CTRL. We look forward to enabling users to achieve the best performance on future releases of Nighthawk with Fire Opal!
Contact us to get started with Fire Opal through the Performance Management Qiskit Function on IBM Quantum Platform.
Hero image: IBM Quantum Nighthawk chip (Source: IBM).