Scaling quantum compilation, and boosting classical ML along the way with GPU-accelerated graph algorithms



Quantum computing promises transformational computational capabilities across many fields, ranging from chemistry and drug discovery to optimization and AI. Nonetheless, “purely quantum” applications such as Shor’s factoring algorithm remain many years away from achieving relevant performance. Delivering commercially-relevant applications and broadening adoption will likely require new insights into how to balance classical and quantum resources.
Hybridization of classical and quantum compute resources is the key trend driving the field towards practical utility. In the hybrid paradigm, quantum processing units (QPUs) become a specialized compute resource complementing a range of other deployed technologies such as GPUs, CPUs, and memory, delivering overall augmented computational capabilities for key problems.
Unlocking the power of hybrid quantum-classical computing
The real benefits of hybrid quantum computing come in how the various compute modalities interact. They are not statically running in parallel, but rather constantly intersecting as key tasks – both in the core computation and also in critical supporting tasks – are shared between systems. Thus, a key challenge is building interfaces across processor types.
At Q-CTRL, we develop AI-powered infrastructure software for QPUs that improves the performance and utility of quantum computers. A core part of that is orchestrating the interoperability of QPUs, GPUs, and CPUs, removing barriers so users can fully leverage the entire compute stack. In this area, we’re a category-defining business and constantly pushing the envelope of what’s possible through our original research.
In a recent publication, researchers from Q-CTRL, NVIDIA, and Oxford Quantum Circuits (OQC) showed that rethinking well-established algorithms to leverage GPU-accelerated computing can help remove a central bottleneck in the task of compilation for a QPU. This work has shown exceptional performance gains – hundreds of times in wallclock speedup – enabling the compilation of resource-intensive quantum circuits in record time, and charting a pathway to true large-scale quantum computing.
Together we’re enabling the deployment of quantum computing in real-world high-performance computing (HPC) and data centers. Read on to learn more about this exciting new work!
Pushing the boundaries of quantum compilation
To understand how this work has come about, we have to focus first on a core process in quantum computing called compilation – the process by which abstract algorithmic commands are translated first to an efficient device-specific instruction set and then to true hardware machine language. Improving the quality and speed of compilation is an emerging priority as the field moves towards quantum advantage, and circuit size and complexity grow.
Following from our previous collaboration, we set out to address one of the most significant bottlenecks in quantum circuit compilation. Our core observation centers on the foundational role that computational “graphs” play in quantum compilation and the critical need for parallel graph processing.
Quantum compilers represent both circuits and quantum devices as graphs. First, they take as input a generic quantum program as a list of instructions, where each instruction specifies the qubits it operates on. The compiler uses this information to create a pattern graph where nodes represent qubits and edges represent operations between qubits. This process associates a unique graph with each quantum program. Next, quantum hardware architectures can be represented as data graphs; each physical qubit becomes a node, and native operations between qubits are represented as edges connecting those nodes.
Since qubits vary in their physical properties, one key task of the compiler is to choose a layout that places the program onto the most favorable set of qubits. Layout selection, typically the most time-consuming compiler operation, takes both graphs as input and finds the optimal mapping between them, maximizing certain metrics like expected performance (given device specifications).
Unfortunately, as quantum algorithms and hardware systems scale to thousands of qubits, the number of possible mappings grows exponentially, making optimal layout selection computationally intractable. Simply put, we need new tools to see continued progress in quantum compilation, focusing on the specific mathematical problem underlying layout selection: subgraph isomorphism.
The subgraph isomorphism problem is the bottleneck
The challenge we encounter in layout selection is formally the subgraph isomorphism problem: identifying embeddings of one graph within another while preserving structural relationships.
This problem is central in graph theory with direct relevance to many real-life applications; it deals with the search for recurring structural patterns hidden within massive networks. This task directly enables applications in large-scale network analysis, bioinformatics workflows, and cybersecurity pattern detection. That is, it’s a massively valuable problem to solve.
Despite its importance, this NP-complete challenge has long resisted attempts to scale it to the largest target problems. Existing algorithms rely on backtracking methods that are not amenable to multicore processors, including GPUs. The sequential nature of currently available solutions (like VF2) leaves today's powerful HPC clusters with CPU, GPU accelerators, and emerging QPU resources, underutilized.
This is an area with a lot of ongoing activity. Newer algorithms attempt to incorporate parallelization, but their reliance on backtracking-based search fundamentally limits their scalability. Attempts to leverage GPUs by building custom data structures still present programmability challenges since optimizations are hardware-specific and limit portability across GPUs.
This was the problem we had to solve for the purpose of enhancing quantum compilation, but with a much broader range of benefits. Working with NVIDIA and OQC, we developed a novel solution to this problem that combines insights from the graph database and analytics community, data science techniques, and leverages well-established open source software.
Δ-Motif: Leveraging data science techniques for subgraph isomorphism
To overcome the sequential bottlenecks of existing solutions, we decided to take a fundamentally different approach to the problem.
Our experience examining and using state-of-the-art solutions revealed the need for a highly parallelizable solution that can effectively leverage the hybrid hardware present in current HPC environments, making efficient use of both CPU cores and GPUs. We focused on a generalizable algorithmic approach for massively parallel architectures while maintaining programmability and portability.
In our new solution, instead of “fitting” a graph into a bigger one, we iteratively build the program graph using building blocks found in the hardware graph.
Our new approach, named Δ-Motif, replaces traditional backtracking strategies with a data-centric approach that decomposes the graphs into fundamental motifs (small, reusable building blocks like paths and cycles), representing them in tabular formats and models graph processing with relational database operations like merges and filters. This shift transforms an inherently sequential problem into one that can be executed in parallel at scale, unlocking new levels of efficiency in graph processing.
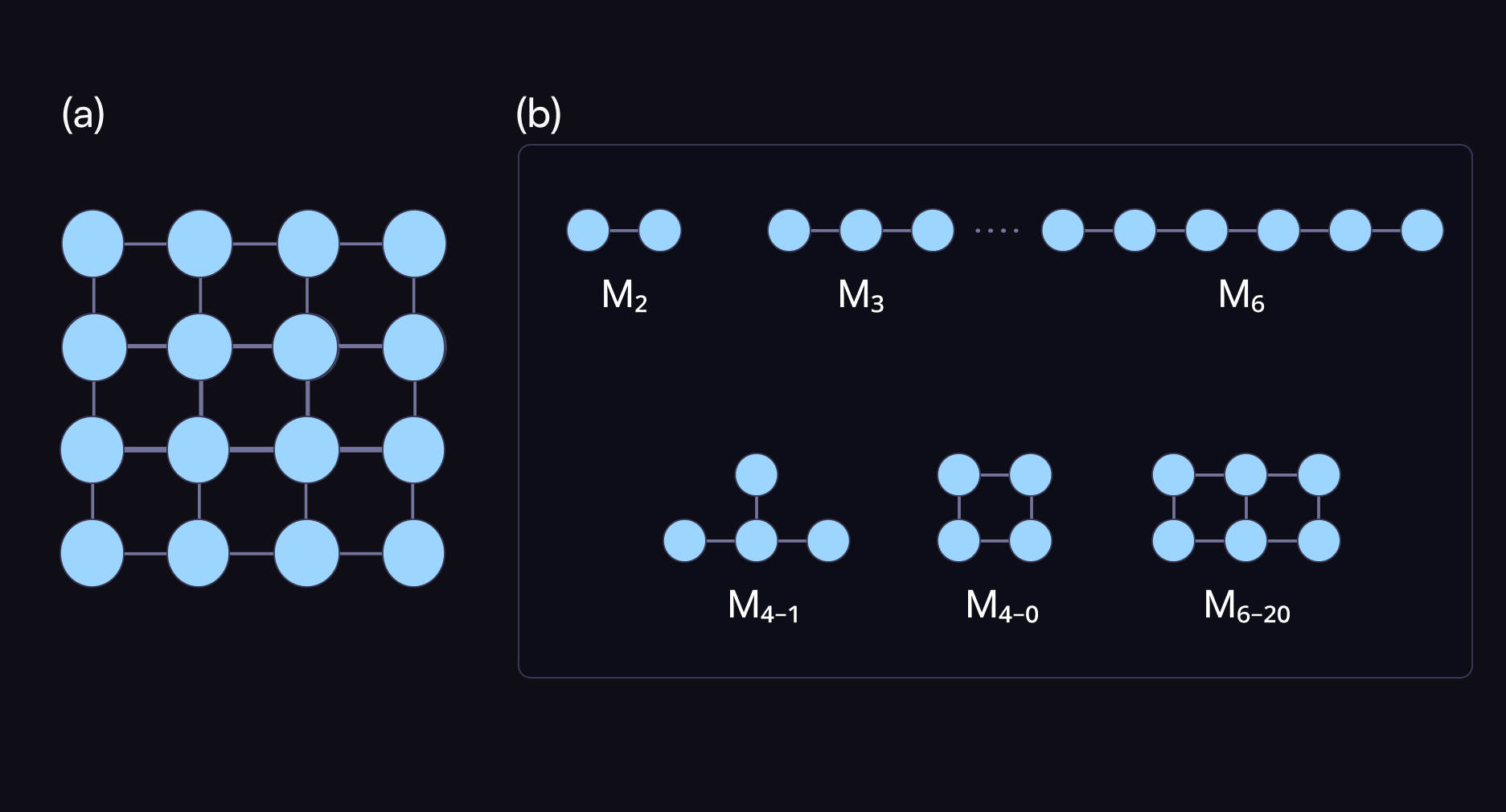
Amazingly, this meant that our new algorithm for subgraph isomorphism could be entirely implemented using well-established open-source libraries: Pandas and Numpy.
Our solution utilizes fundamental table operations, which are conceptually straightforward but can introduce bottlenecks if performance is not top of mind in implementation. For this reason, we chose to build upon NVIDIA RAPIDS as a well-tuned library, ensuring that future improvements to the library will directly benefit our algorithm's performance. Further, by designing our algorithm around these primitives, we can ensure that massive parallelism can be attained via NVIDIA GPUs, while retaining strong performance on CPU-only systems.
Delivering unprecedented performance at scale
Through extensive benchmarking using NVIDIA H200 GPUs, we demonstrate that our algorithm delivers dramatic speedups compared to VF2 as a backtracking baseline. Notably, on benchmarks simulating quantum devices larger than current hardware, we observed nearly 600x speedups.
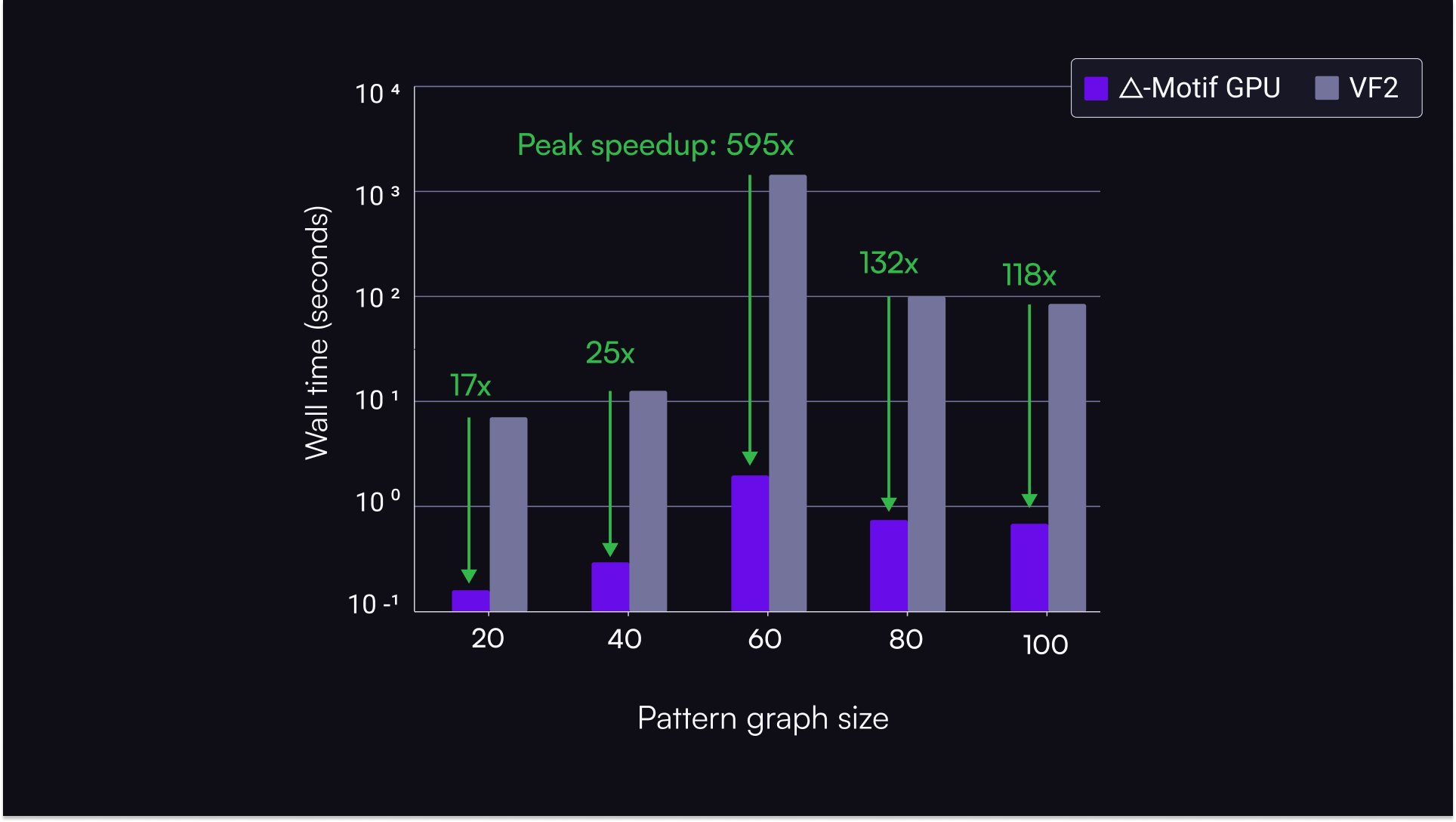
We benchmarked our pipeline on a diverse set of quantum circuits from the QASMBench benchmark suite. Across this varied workload, GPU implementations of Δ-Motif consistently outperform the default implementation by orders of magnitude.

We also benchmarked the raw performance of our new algorithm on tasks common in large graph analysis, using datasets from the SparseSuite Matrix Collection, where again we achieved speedups of up to 380x.
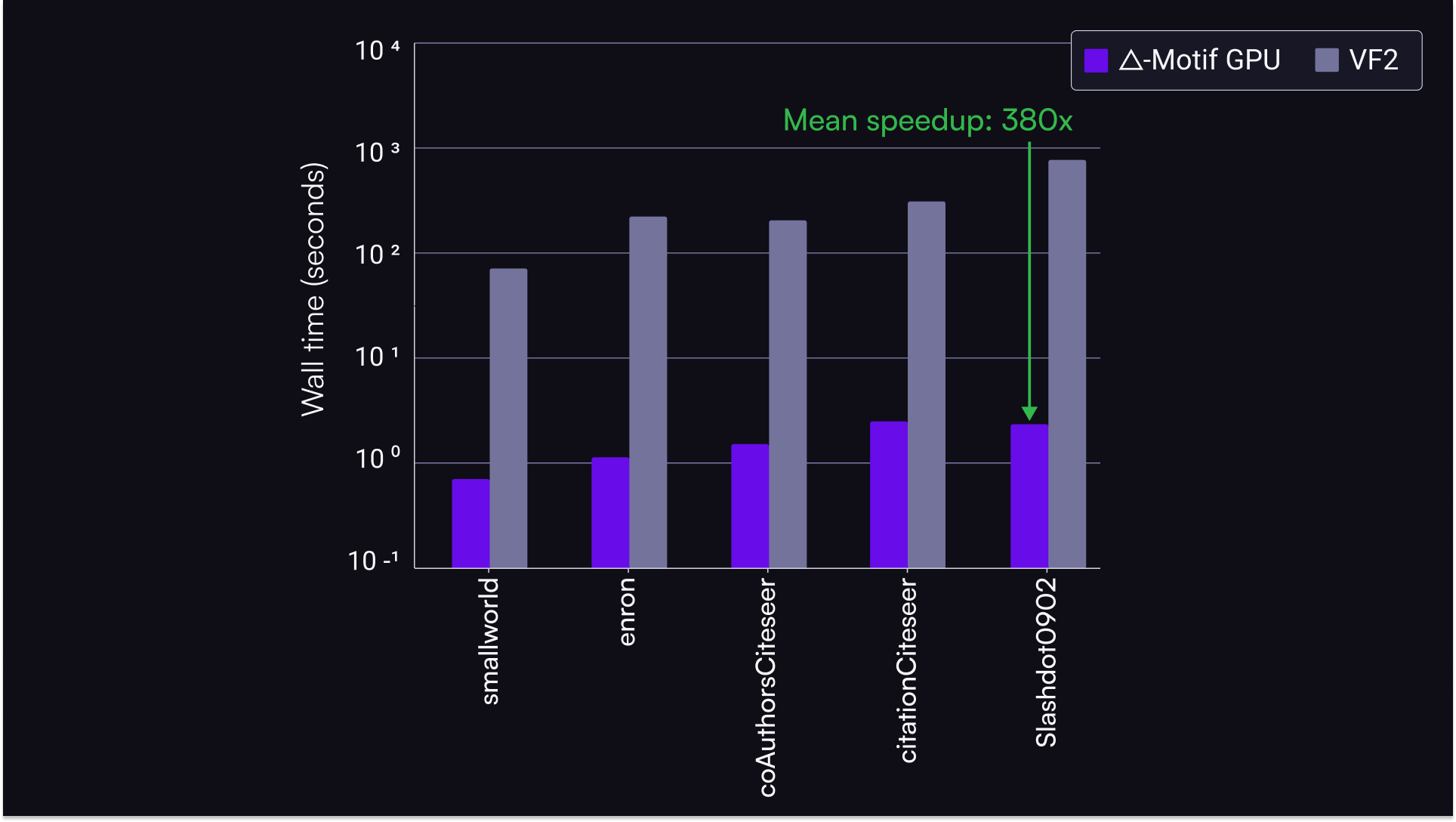
Lowering the barrier for HPC integration
Crucially, the performance gain we achieved comes by leveraging well-established, high-level library functions without requiring teams to develop custom CUDA code. By framing subgraph isomorphism as tabular operations, our approach leverages mature, open-source libraries to deliver HPC-grade efficiency and portability through familiar data science tools. This makes massive parallelism accessible to a much broader community of practitioners that can leverage their current data science tools to access the scale of HPC systems, lowering barriers to adoption while enabling real-world impact across industries.
In this case, an innovation borne out of the need to improve quantum-compiler performance using GPUs in a hybrid setting now also has the potential to transform a wide range of critical computational tasks. It shows directly that pushing forward on hybrid quantum computing can deliver unexpected benefits that can have high-value impacts in the near term.
As networks and data structures grow in size, complexity, and ubiquity, the urgency for scalable solutions is only increasing. Efficient graph processing presents a proving ground for a class of problems where the limits of classical computing are most visible, and where quantum computers have the potential to unlock entirely new approaches to execution.
By reformulating graph problems so they can harness both massively parallel classical resources and emerging quantum architectures, we can bridge the gap between today’s HPC bottlenecks and tomorrow’s quantum-enabled breakthroughs, accelerating the era of advantage in quantum computing.
Explore the full algorithm and benchmark results in our co-authored technical manuscript.
Get in touch if you are interested in implementing these solutions in your hybrid workflows.